RAG 效果评测
适用读者:RAG 调优人员、内容运营人员
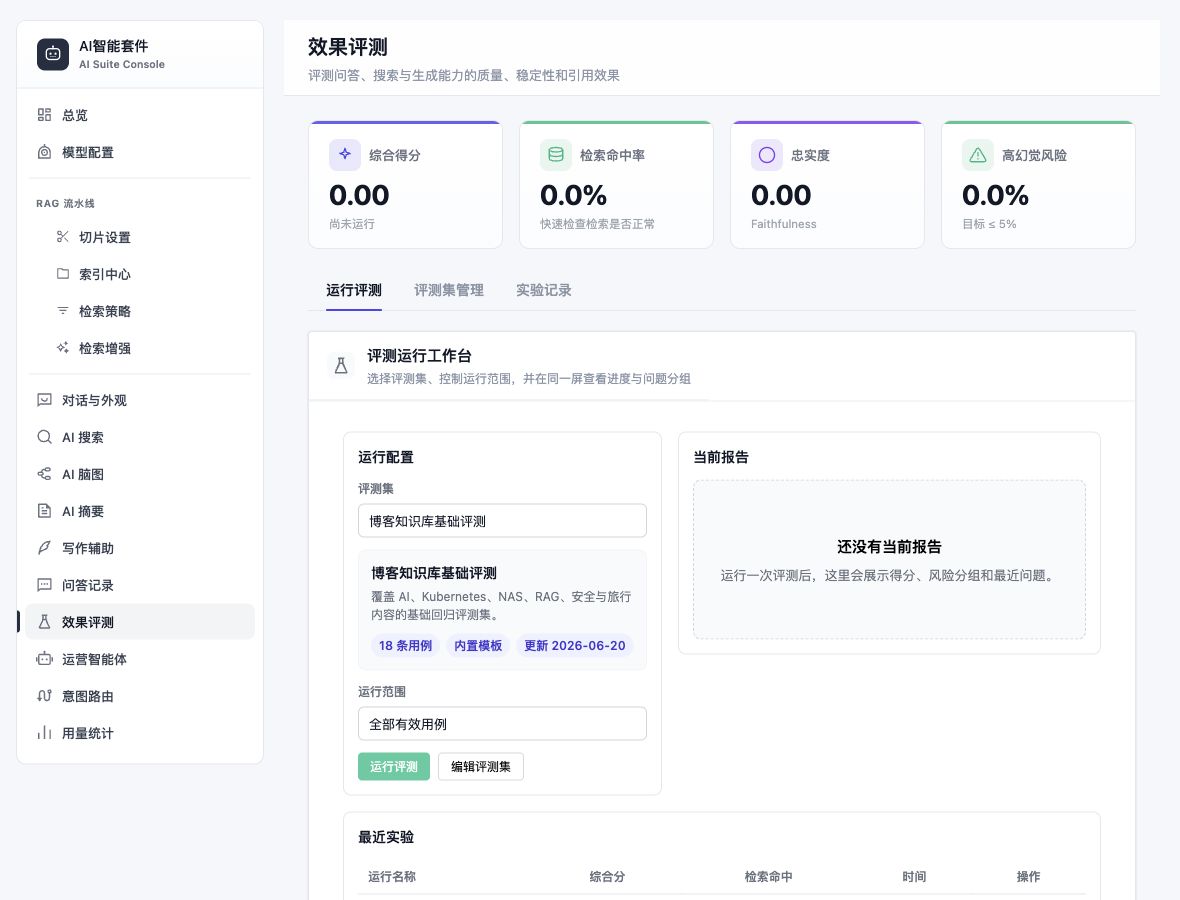
效果评测使用持久化数据集批量执行问答,并由评审模型检查相关性、正确性、忠实度、完整性、引用准确性和幻觉风险。
数据集
每个用例包含:
- 问题
question - 参考答案
referenceAnswer - 期望来源
expectedSources - 标签
tags
默认模板用于示例,不应直接当成你站点的真实基准。优先从高频访客问题、重要文章和历史点踩中建立自己的数据集。
运行评测
- 新建或复制数据集。
- 检查参考答案和来源文章。
- 提交运行,获得
runId。 - 页面轮询任务进度。
- 完成后查看总分、检索命中率、忠实度和高风险用例。
- 调整配置后用同一数据集再次运行。
指标解释
| 指标 | 含义 |
|---|---|
| 检索命中率 | 期望来源是否进入检索结果 |
| 相关性 | 回答是否针对问题 |
| 正确性 | 是否符合参考答案 |
| 忠实度 | 是否得到检索上下文支持 |
| 完整性 | 是否覆盖关键点 |
| 引用准确性 | 引用是否支持对应结论 |
| 幻觉风险 | 是否包含无依据内容 |
成本
每个用例至少包含回答和评审调用,可能同时产生 Embedding、Rewrite、HyDE 和 Rerank 成本。先运行小数据集,确认预算后再扩大。
对比原则
- 固定数据集和模型,再比较检索参数。
- 或固定检索参数,再比较模型。
- 不要同时改变模型、切片、Prompt 和增强策略。
- 保存运行记录,避免只看当前一次结果。
相关接口见 Console API。